Kaspar Märtens
Hi! I'm a machine learning researcher developing foundation models for biology, with a PhD in Statistical Machine Learning from Oxford and expertise in probabilistic and generative modelling. At Synthesize Bio, I work on the models behind our virtual lab: systems that predict the outcomes of biological experiments, from cellular perturbations to human-level readouts. My recent work explores how LLMs can advance virtual cell models.

Selected Work

LangPert: LLM-Driven Contextual Synthesis for Perturbation Prediction
MLGenX at ICLR 2025 · Oral
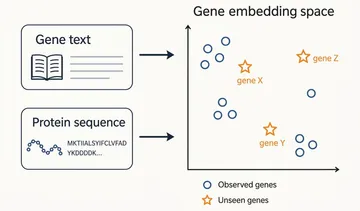
Enhancing Generative Perturbation Models with LLM-Informed Gene Embeddings
MLGenX at ICLR 2024
2026 GenePT Revisited: Do Better Text Embeddings Make Better Gene Embeddings? bioRxiv 2025 SynthPert: Enhancing LLM Biological Reasoning via Synthetic Reasoning Traces Arxiv 2020 BasisVAE: Translation-Invariant Feature-Level Clustering with VAEs AISTATS
All publications → Writing
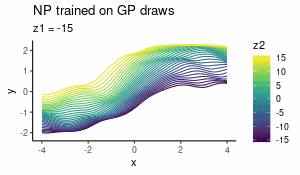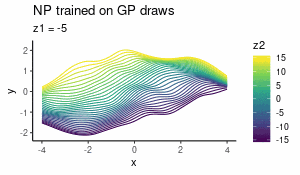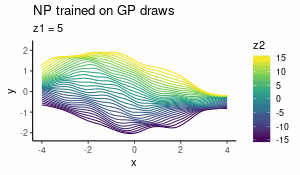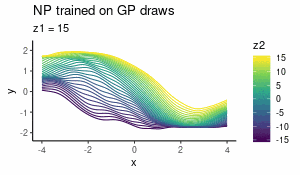
Aug 2018
Neural Processes as distributions over functions
What Neural Processes are and how they behave as a prior over functions — interactive visualisations included.